Mode Partitioning Method Implemented with ADCB specimen
This notebook is an example implemention of the mode partitioning method with BK criteria defined in section 3.1 on Mode Partitioning Method, presented in the master thesis title Finite Element Model For Interfaces In Compatibilized Polymer Blends.
Outline
Create design of experiments. \(\checkmark\)
Run simulations. \(\checkmark\)
Read odb data. \(\checkmark\)
Generate R curves. \(\checkmark\)
Extract Fracture toughness samples from R curves. \(\checkmark\)
Predict mode ratio based on the sampled fracture toughness and assumed mixed-mode energy criteria. \(\checkmark\)
Preprocessing
Import required modules.
[5]:
# imports
import json
import numpy as np
from IPython import display
from scipy.stats import qmc
from matplotlib import pyplot as plt
%matplotlib inline
Create a dictionary of the variables required to generate and run the Abaqus/CAE model that are common for all the tests.
[2]:
TestSet = 'ADCB_AbqImp' # Folder name for the set of experiments
# Constants for the experiment
fixed = {'JobID':'ADCB_AbqImp',
'Length':100,
'Width':25,
'tTop':1.5,
'tBot':5.1,
'tCz':0.2,
'Crack':60,
'DensityBulkTop':1.8e-9,
'ETop':(109000.0, 8819.0, 8819.0, 0.34, 0.34, 0.38, 4315.0, 4315.0, 3200.0),
'DensityBulkBot':1.8e-9,
'EBot':(109000.0, 8819.0, 8819.0, 0.34, 0.34, 0.38, 4315.0, 4315.0, 3200.0),
'DensityCz':1.8e-9,
'StiffnessCz':1250,
'GcNormal':0.42,
'GcShear':4.2,
'gFailureNormal':0.2,
'gFailureShear':0.2,
'MeshCrack':3,
'MeshX':1,
'MeshZ':0.6,
'Displacement':20,
'nCpu':1,
'nGpu':0,
'userSub':{'type':'None', 'path':'C:\\Users\\nandi\\Documents\\Abaqus Work Directory\\MixedMode\\FDF.for', 'intProp':[]},
'submit':True}
Further, define the variables that have to be changed for each experiment.
[ ]:
n_pts = 3 # number of samples requied from the sobol sequence
n_variables = 1 # number of variables
l_bounds = [2.0] # lower limits for sampling
u_bounds = [3.0] # upper limits for sampling
sampler = qmc.Sobol(d=n_variables, seed=1896) # setting up the sequence generator
sample = sampler.random(n_pts) # sampling the points
pts = qmc.scale(sample, l_bounds, u_bounds).tolist() # scaling them using the sample bounds
# Defining a dictionary with list of values for the variable.
doe = {'bkPower':pts}
doe['nPoints'] = [x for x in range(len(pts))]
Running simulations
The run_sim function iterates through each point in the design of experiments (doe) and creates an instance of the input data by assigning the values for the variables from their corresponding lists in the doe dict along with all the fixed variables. For example, in this case, the ith instance will be assigned a value of pts[i] for the bkPower variable along with all the variables in the fixed dict. Further, for each instance, a folder point_i is created and set as
working directory. Finally, the abaqus python script in czmtestkit.abaqus_modules.ADCB2 is executed in the working directory with instance input data. The czmtestkit.abaqus_modules.ADCB2 funciton creates a unit width CAE model with plain strain conditions and runs the finite element simulation of the model using Abaqus/CAE resulting in .odb file with the output database. The history of displacement and reaction force in the active degrees of freedom of the load edge are recorded
using the Abaqus/CAE history output functionality and can be extracted from the .odb file. czmtestkit.abaqus_modules.historyOutput function extracts this data and generates a .csv with the data. Further, since czmtestkit.abaqus_modules.ADCB2 creates a unit width CAE model, the Results function returns a dictionary with the magnitudes of the displacement and reaction force adjusted to required width by multiplying the actual width. run_sims iteratively runs these abaqus
and python functions for each instance. The input parameter and output from all the instances are saved to the Database.json file in the test directory.
[5]:
from czmtestkit.py_modules import Results
from czmtestkit.py_modules import run_sim
run_sim(TestSet, doe, fixed, 'czmtestkit.abaqus_modules.ADCB2', 'czmtestkit.abaqus_modules.historyOutput', Results)
Reading and plotting the output data.Read the database and plot the output data.
[6]:
# Reading output file
file = open(os.path.join(TestSet, 'Database.json'), 'r')
data_text = file.readlines()
Data = []
for entry in data_text:
Data.append(json.loads(entry))
# Extracting output data and input variables
U = []
RF = []
eta = []
for entry in Data:
U.append(np.array(entry['Displacement']))
RF.append(np.array(entry['Reaction Force']))
eta.append(entry['bkPower'])
file.close()
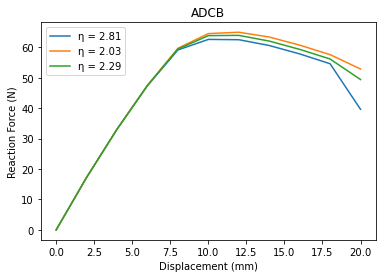
# Plotting the data
fig, ax = plt.subplots()
for i in range(len(eta)):
ax.plot(U[i], RF[i], label='\u03B7 = {:.2f}'.format(eta[i]))
ax.set_title('ADCB')
ax.set_xlabel('Displacement (mm)')
ax.set_ylabel('Reaction Force (N)')
ax.legend()
[6]:
<matplotlib.legend.Legend at 0x2cd5f53c220>
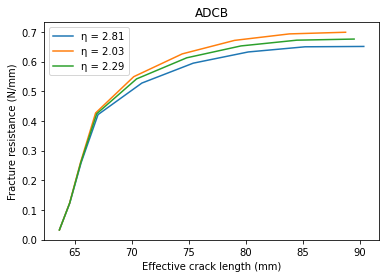
Post Processing
The class czmtestkit.py_modules.ADCB is the analytical models from appendix B in the master thesis title Finite Element Model For Interfaces In Compatibilized Polymer Blends and the class method czmtestkit.py_modules.ADCB.rCurve converts the displacement and reaction force data to fracture resistance curves (r Curves) for a given instance. The czmtestkit.py_modules.run_analysis function iteratively runs the czmtestkit.py_modules.ADCB.rCurve method for all the instances
(dictionaries) in Database.json of the TestSet directory and appends the generated r Curve data back to the database.
[7]:
from czmtestkit.py_modules import ADCB
from czmtestkit.py_modules import run_analysis
model = ADCB()
run_analysis(TestSet, model.rCurve)
Read the database and plot the output data.
[8]:
# Reading output file
file = open(os.path.join(TestSet, 'Database.json'), 'r')
data_text = file.readlines()
Data = []
for entry in data_text:
Data.append(json.loads(entry))
# Extracting output data
a_e = [] # effective crack length
gR = [] # fracture toughness / fracture resistance
eta = []
for entry in Data:
a_e.append(np.array(entry['Crack Length']))
gR.append(np.array(entry['Fracture Resistance']))
eta.append(entry['bkPower'])
file.close()
# Plotting
fig, ax = plt.subplots()
for i in range(len(eta)):
ax.plot(a_e[i], gR[i], label='\u03B7 = {:.2f}'.format(eta[i]))
ax.set_title('ADCB')
ax.set_xlabel('Effective crack length (mm)')
ax.set_ylabel('Fracture resistance (N/mm)')
ax.legend()
[8]:
<matplotlib.legend.Legend at 0x2cd5f4c6c70>
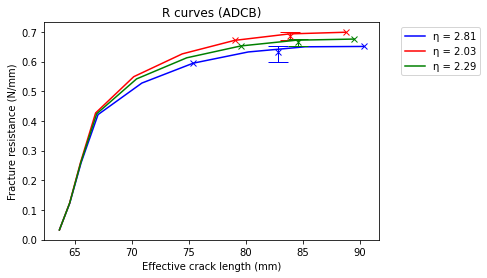
Sample the plateaus in the r Curves for fracture toughness estimation and plot the sample statistics (mean and confidence intervals).
[11]:
# defining the plateau region
a_l = 75 # Crack length at plateau start
a_u = 110 # Crack length at plateau end
# picking samples and calculating the sample statistics
## Initializing empty vectors
g_sample = []
alim_sample = []
glim_sample = []
Gt = []
CI = []
## Iterating through the tests
for i in range(len(eta)):
ind = np.where(np.logical_and(a_e[i]>=a_l, a_e[i]<=a_u)) # Fetching samples with crack length within the limits choosen
g_sample.append(gR[i][ind[0].tolist()]) # Sampling fracture tougness corresponding to the sampled crack lengths
alim_sample.append(np.array([a_e[i][ind[0][0]], a_e[i][ind[0][-1]]])) # Crack length sample limits
glim_sample.append(np.array([gR[i][ind[0][0]], gR[i][ind[0][-1]]])) # Fracture toughness sample limits
mean = g_sample[i].mean() # Fracture toughness sample mean
p025 = np.percentile(g_sample[i], 2.5) # Fracture toughness lower quartile
p975 = np.percentile(g_sample[i], 97.5) # Fracture toughness upper quartile
Gt.append(mean) # Appending to list of means of all the tests
CI.append([[mean - p025], [p975 - mean]]) # Appending to list of confidence intervals of all the tests
# Plotting the r-Curve with fracture toughness samples and statistics
c = ['b', 'r', 'g', 'mediumvioletred', 'purple','olive','grey','maroon','teal','m']
# Iterating through Tests 1, 2, and 3
for i in range(len(eta)):
plt.plot(a_e[i], gR[i], label='\u03B7 = {:.2f}'.format(eta[i]), color=c[i])
plt.plot(alim_sample[i], glim_sample[i], 'x', color=c[i])
plt.errorbar(alim_sample[i].mean(), Gt[i], yerr=CI[i], fmt = 'x', color=c[i], ecolor=c[i], elinewidth = 1, capsize=10) #label='Mean: \u03B7 = {:.3f}'.format(eta[i])
plt.legend(bbox_to_anchor=(1.05, 1.0), loc='upper left')
plt.xlabel('Effective crack length (mm)')
plt.ylabel('Fracture resistance (N/mm)')
plt.title('R curves (ADCB)')
plt.show()
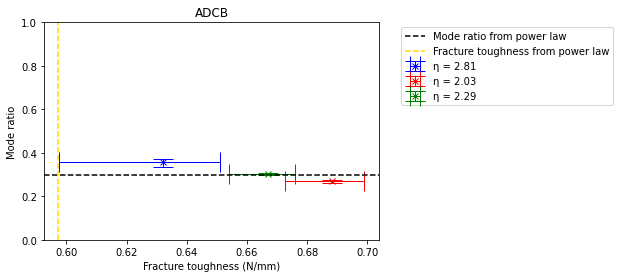
Since, the BK criterion was used to in the Abaqus/CAE model, the same is used to estimate a mode ratio for each estimated fracture toughness.
[13]:
def BK_criteria(gT, GIc, GIIc, eta):
return ((gT - GIc)/(GIIc - GIc))**(1/eta)
The fracture toughness for one instance of the doe is a list of values sampled from its r Curve. Predicting the mode ratio for this list results in a list of predicted mode ratios for the instance. The means and confidence intervals of the lists of predicted mode ratios and the fracture toughness for each instance of the test are plotted here.
[14]:
# Initializing empty vectors
B = []
b_samp = []
CI_B = []
# Predicted ADCB mode ratios and sample statistics
for i in range(len(eta)):
b = BK_criteria(g_sample[i], fixed['GcNormal'], fixed['GcShear'], eta[i])
b_samp.append(b)
mean = b.mean()
p025 = np.percentile(b, 2.5)
p975 = np.percentile(b, 97.5)
B.append(mean)
CI_B.append([[mean - p025], [p975 - mean]])
plt.errorbar(Gt[i], B[i], xerr=CI[i], yerr=CI_B[i], fmt = 'x', label='\u03B7 = {:.2f}'.format(eta[i]), color=c[i], ecolor=c[i], elinewidth = 1, capsize=10)
## Plot area steup
plt.axhline(y=0.297807890402863, color='black', linestyle='--', label='Mode ratio from power law')
plt.axvline(x=0.597068684259331, color='gold', linestyle='--', label='Fracture toughness from power law')
plt.legend(bbox_to_anchor=(1.05, 1.0), loc='upper left')
plt.ylim((0, 1))
plt.xlabel('Fracture toughness (N/mm)')
plt.ylabel('Mode ratio')
plt.title('ADCB')
[14]:
Text(0.5, 1.0, 'ADCB')